작성자: 김선재
한 번쯤 BERT 나 GPT, BART, ERNIE 등등의 NLP 모델들을 접해보았다면, 그 모델들의 놀라운 결과를 자신이 가진 데이터나 나만의 작업에 적용하기 위해 paperswithcode나 google로 관련 코드를 찾아봤을 것입니다.
보통 모델들에 대한 python 코드나 notebook 파일을 찾는 경우 github나 gitlab에 코드나 노트북이 있는 경우가 많아 거기에서 포크하는 경우가 많습니다.
그런데 NLP 분야의 경우 다른 유명한 인공지능 분야인 computer vision 과 비교해봐도 남다른 부분이, 이 코드나 노트북들이 github에 존재하지만 이와 별도로 또 하나의 모듈로써도 묶여 있어 마치 tensorflow나 pytorch 처럼 필요한 모델들만을 불러올 수 있다는 점입니다.
이 하나의 모듈이 transformers 모듈입니다. Hugging face는 이 transformers 모듈 뿐만 아니라 datasets 모듈, 각 모델에 대한 일관된 형식의 문서를 저장하는 model hub와 외부에서 학습시킨 nlp 모델들을 참조할 수 있는 inference api 를 모두 관리 및 제공하는 회사입니다.
Hugging Face 의 웹사이트 에서는 거의 모든 NLP 모델들을 찾아보실 수 있습니다.
앞서 말씀드린 bert, gpt, bart, ernie 뿐만 아니라, Roberta, 구글의 T5 와 더불어 이런 모델들에서 비롯되어진 구체적인 모델들을 살펴볼 수 있습니다.
일례로 bert의 경우 초기 모델은 uncased, 즉 대소문자를 소문자로 변환해서 사용하는 모델이었는데 추후 hugging face 회사 측에서 large uncased 모델, 즉 대소문자를 대문자로 변환해서 사용하는 모델, large cased 모델, multilingual uncased 모델 등등으로 다양한 모델들로 확장시켰습니다.
이러한 모델들은 from transformers import BertModel 로 불러올 수 있습니다.
물론, transformers 모듈을 통해 pretrained 되어진 모델에서 바꾸고 싶은 파라미터들을 조정할 수도 있습니다.
Bert 모델에서 조정할 수 있는 파라미터들은 다음 을 참고해주시면 됩니다.
같은 사이트에 transformers 모듈에 있는 bert 외의 다른 모델들의 자세한 내용도 담겨 있습니다.
Hugging Face에서는 모델들 뿐만 아니라 데이터셋을 python으로 불러올 수도 있습니다.
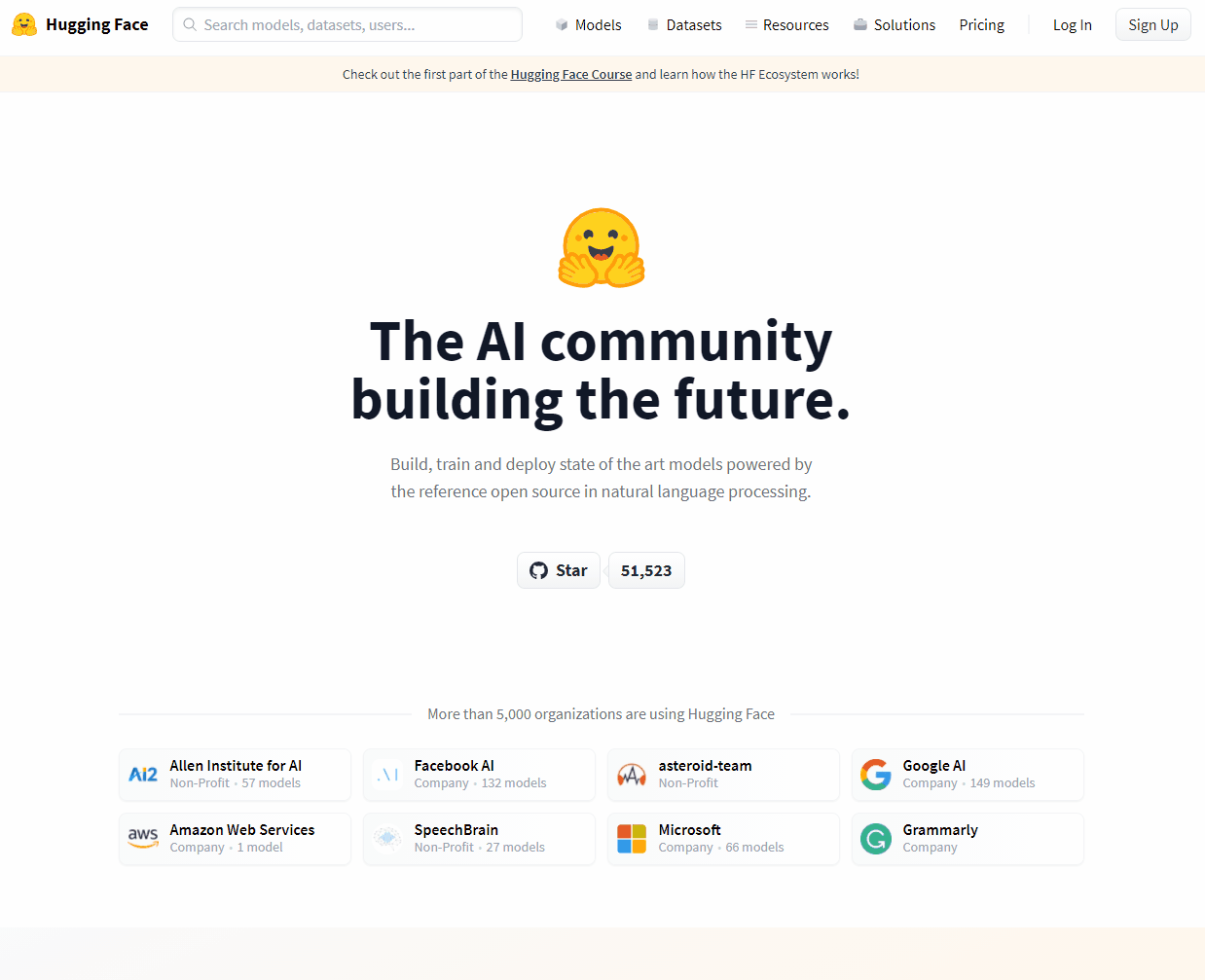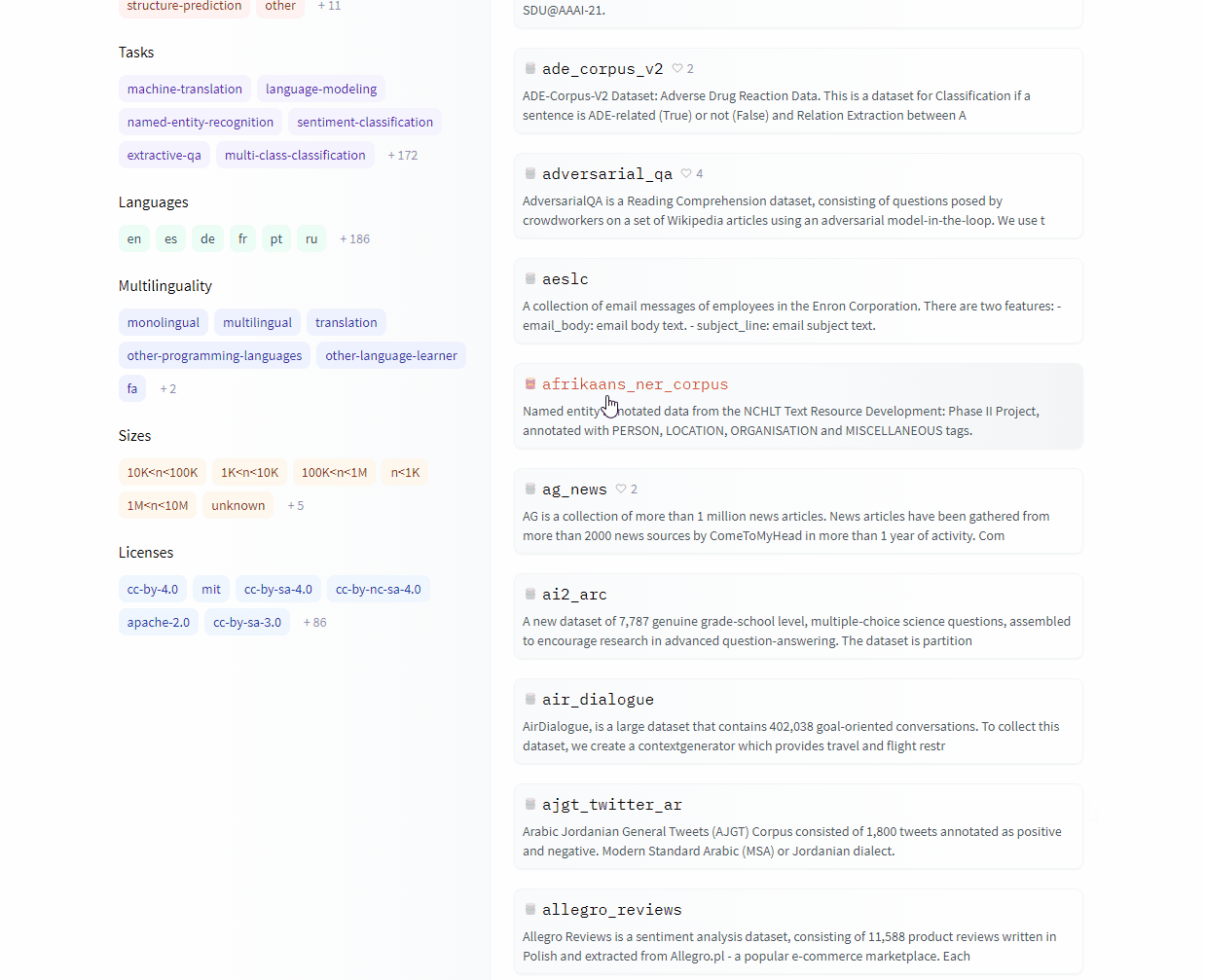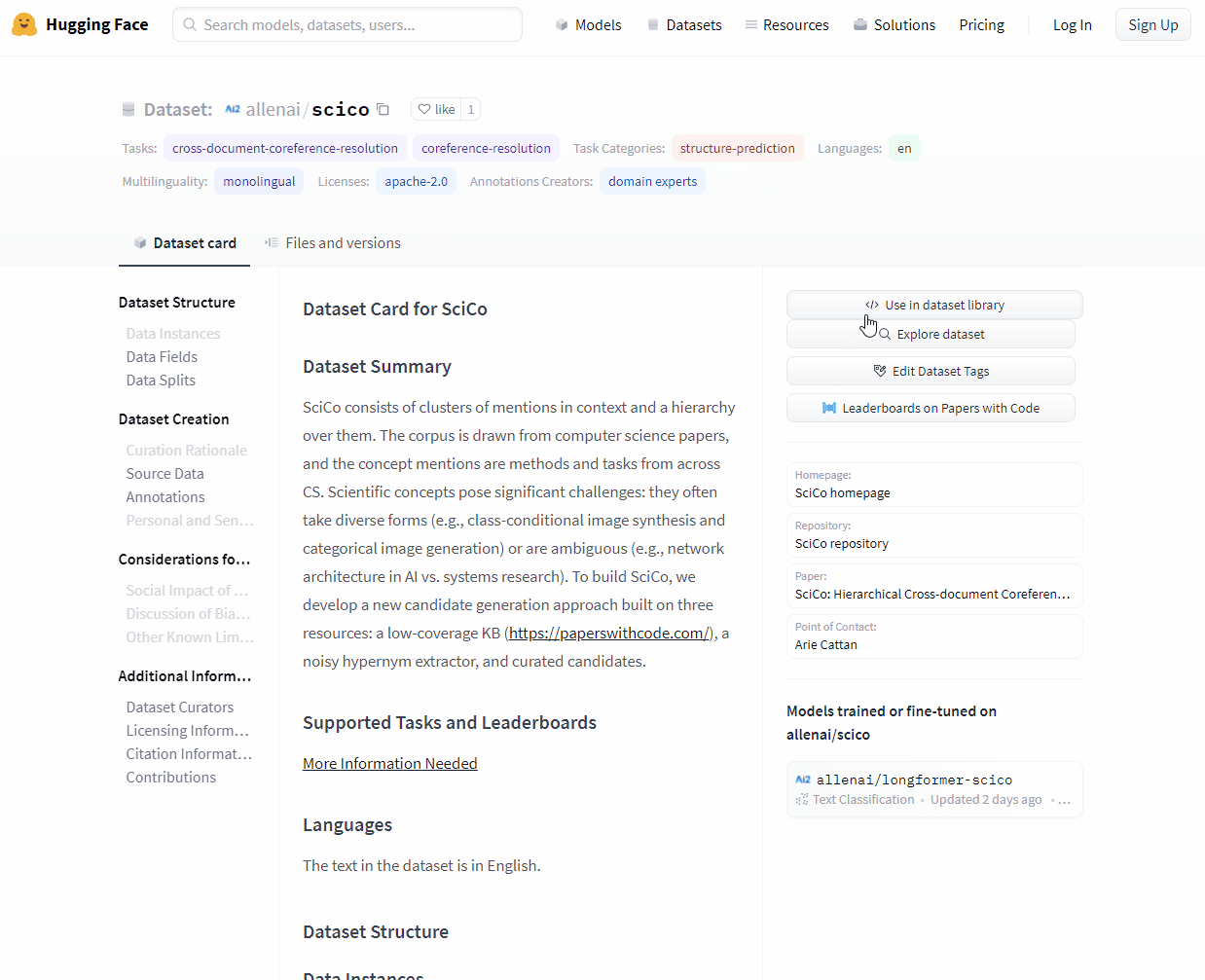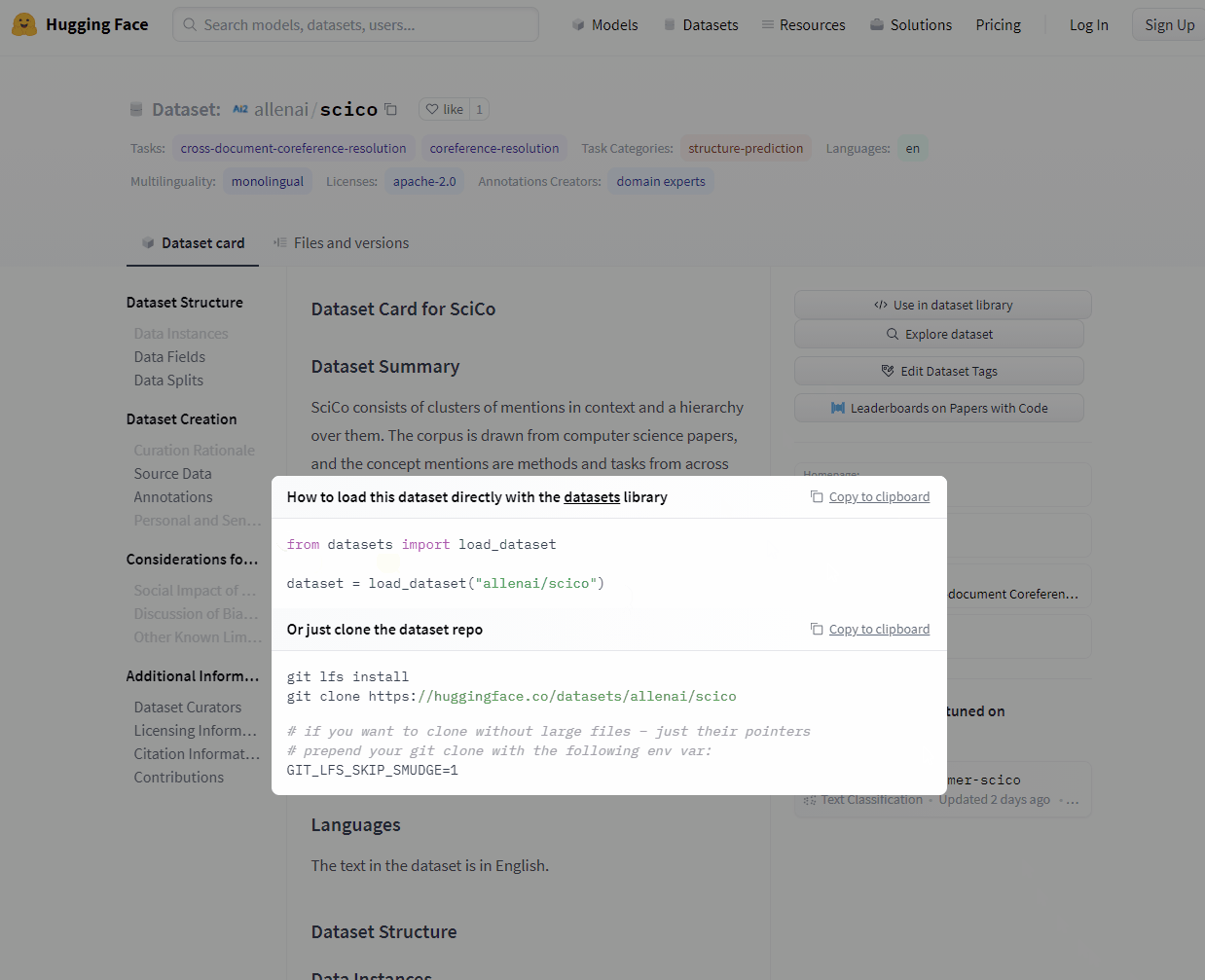
예를 들어, 다음과 같은 코드를 사용하면 과학 분야의 논문들에 자주 쓰이는 영어 단어들의 데이터셋을 불러올 수 있게 됩니다.
from datasets import load_dataset
dataset = load_dataset(“allenai/scico”)
이 밖에 다양한 데이터셋을 다음처럼 Hugging Face의 홈페이지를 참고해 불러올 수 있습니다.
이처럼 hugging face의 transformers 모듈이나 datasets 모듈은 필요한 모델이나 데이터를 python의 점(.), 괄호(( )) 등으로 호출한다는 점에서 tensorflow, pytorch의 패키지와 사용 방법이 매우 유사합니다. 다만 hugging face의 모듈들이 tensorflow 나 pytorch 를 이용해 만들어진 고차원(?) 모듈이라는 점에서 tensorflow 나 pytorch 같은 패키지와는 개념이 조금 다릅니다. 이러한 high-level api는 모델을 적용하는 단계에서 데이터와 학습 방법에 대한 아이디어만 있다면 매우 빨리 모델을 생성하고 학습시킬 수 있습니다. 하지만, 어떤 모델이나 데이터에 대한 추후 연구를 위해서는 결국 코드를 짠 사람이나 논문 저자의 git repo를 포크해서 코드, 방법론을 하나하나 살펴봐야 합니다. 그런 분들에게는 hugging face 가 조금 불편할 수도 있습니다. 그럼에도 불구하고 자칫 분산될 수도 있고, 중복해서 개발될 수 있는 자연어 처리 관련 오픈 소스들을 한 곳으로 모았다는 점에서 hugging face의 모듈들의 의의가 큽니다. 지금 hugging face를 이루는 대부분의 언어는 영어, 스페인어, 독일어 등의 서양권 언어들입니다. 한국어의 경우 아직 나무위키 데이터베이스 덤프과 같은 다양한 데이터셋이 모듈에 포함되어 있지 않습니다. 모델도 마찬가지로 한국어 nlp를 위해 많은 분들께서 쓰시는 konlpy 패키지나 SKTBrain의 KoBERT는 transformers 모듈에 포함이 아예 안되어 있거나 포함되어 있더라도 코드만 포함되어 있고 설명이 별개의 웹사이트에 적혀 있습니다. 이것은 아마도 한국어 NLP 커뮤니티 내에 hugging face가 잘 알려지지 않은 탓이 클 것 같습니다. 이 글을 필두로 nlp 데이터셋과 모델들을 하나로 모으려는 hugging face 의 노력에 한국어 NLP 커뮤니티가 더욱 활발히 동참했으면 좋겠습니다.
감사합니다.